

Sommaire
- Google fixe 2029 comme deadline post-quantique : Ethereum est prêt, Bitcoin non
- Ethereum Economic Zone : Gnosis et l’Ethereum Foundation veulent unifier l’écosystème des Layer 2
- Stablecoins : Circle chute de 20%, Coinbase perd 10% avec la fin programmée des récompenses
- Anza dévoile Solana Constellation : des cycles de 50 ms pour concurrencer Hyperliquid
- Ce Coin Hebdo est soutenu par OKX
- Google dévoile TurboQuant : l’algorithme qui compresse la mémoire des LLM par 6 sans perte de précision
- Les marchés vendent d’abord, réfléchissent après : le paradoxe de Jevons appliqué à la DRAM
- Le paradoxe de Jevons : pourquoi consommer moins de mémoire RAM pourrait en faire vendre plus
- Aave V4 veut transformer 6 milliards $ de liquidités dormantes en machine à rendement
- Binance durcit ses règles : les nouvelles sanctions contre les market makers manipulateurs
Google fixe 2029 comme deadline post-quantique : Ethereum est prêt, Bitcoin non
Google vient de fixer 2029 comme deadline interne pour migrer ses services d’authentification vers la cryptographie post-quantique.
Ce calendrier est bien plus agressif que les recommandations du NIST (2035) ou de la NSA (2031).
L’entreprise Google a déjà commencé les travaux : Android 17 embarque des signatures résistantes au quantique, Google Chrome gère l’échange de clés PQC, Google Cloud vend des solutions aux entreprises.
Le problème quantique touche le secteur des crypto monnaies de plein fouet : les blockchains s’appuient sur la cryptographie à courbes elliptiques (ECDSA) pour signer les transactions.
Un ordinateur quantique suffisamment puissant exécutant l’algorithme de Shor pourrait dériver les clés privées à partir des clés publiques exposées sur la blockchain.
L’Ethereum Foundation a pris le sujet au sérieux depuis l’année 2018 et a lancé cette semaine pq.ethereum.org, un hub dédié, et coordonne plus de 10 équipes clients sur des devnets hebdomadaires. Sa roadmap prévoit la migration à travers quatre hard forks, du registre de clés post-quantique au consensus PQ complet.

Bitcoin, de son côté, n’a aucun plan coordonné, aucune roadmap, aucun programme d’ingénierie multi-équipe. Nic Carter, pourtant l’un des plus fervents défenseurs de Bitcoin, a qualifié l’approche d’Ethereum de “best in class” et celle de Bitcoin de “worst in class”.
Une proposition BIP-360 sur Bitcoin existe pour ajouter un type de sortie résistant au quantique, mais elle n’a reçu aucun soutien des développeurs principaux.
Google peut fixer une deadline parce que Google contrôle son infrastructure.
Ethereum peut planifier parce que sa fondation coordonne l’effort.
Bitcoin n’a ni l’un ni l’autre et c’est précisément ce qui rend l’annonce de Google inquiétante pour le réseau.
Ethereum Economic Zone : Gnosis et l’Ethereum Foundation veulent unifier l’écosystème des Layer 2
Gnosis et la Ethereum Foundation lancent l’Ethereum Economic Zone (EEZ), un framework L1↔L2 conçu pour mettre fin à la fragmentation de l’écosystème rollup.
Les rollups L2 ont résolu le scaling, mais chacun fonctionne en silo : liquidité séparée, bridges coûteux et protocoles obligés de se déployer plusieurs fois…
L’Ethereum Economic Zone (EEZ) propose une composabilité synchrone entre Ethereum mainnet et les rollups participants : un smart contract sur un rollup EEZ pourra appeler un contrat sur mainnet (ou un autre rollup) et recevoir une réponse au sein d’une même transaction.
Résultat : une exécution atomique à travers les chaînes, avec des garanties ancrées dans Ethereum, une liquidité partagée, un modèle de sécurité unifié, et ETH qui reste le gas token et la couche de settlement.
Le projet est porté côté technique par Jordi Baylina, le fondateur de Zisk, un stack de proving haute performance. Gnosis apporte un track record solide : Safe (58 milliards sécurisés) CoW Protocol et la Gnosis Chain (7 ans sans downtime). L’EEZ Association, basée en Suisse, développera le tout en open source. Parmi les premiers membres : Aave, Titan, Beaver Build, Centrifuge et xStocks.
Les spécifications techniques et benchmarks sont annoncés pour les semaines à venir.
Stablecoins : Circle chute de 20%, Coinbase perd 10% avec la fin programmée des récompenses
L’action Circle a perdu 20% mardi 24 mars.
Le déclencheur : un brouillon du Clarity Act qui interdirait aux exchanges de verser des récompenses sur les soldes passifs de stablecoins. Le GENIUS Act de juillet 2025 bloquait les versements directs par les émetteurs de stablecoins mais laissait les plateformes de crypto monnaies libres. Le nouveau texte des sénateurs Alsobrooks et Tillis ferme cette porte.

Coinbase a perdu près de 10% dans la foulée, l’USDC représentant environ 20% de ses revenus selon Mizuho.
Le lobbying des banques traditionnelles explique ce durcissement. Ces établissements considèrent les programmes de récompenses sur stablecoins comme une menace directe pour leurs dépôts, dont ils ont besoin pour octroyer des crédits. Le Clarity Act autoriserait toutefois les récompenses “liées à l’activité” (paiements, trading, lending), ce qui nuance l’interdiction.
Anza dévoile Solana Constellation : des cycles de 50 ms pour concurrencer Hyperliquid
Anza a dévoilé Constellation, un protocole de proposeurs multiples concurrents (MCP) qui s’attaque au problème fondamental des blockchains actuelles : le monopole du leader de bloc.
Sur Solana aujourd’hui, un leader rotatif voit toutes les transactions en attente et contrôle seul leur inclusion et leur ordre, une porte ouverte au MEV : front-running, sandwich attacks et censure des transactions sélective.

Constellation remplace ce modèle par 16 proposeurs simultanés et 256 attesteurs qui forcent cryptographiquement le leader à inclure toute transaction suffisamment attestée. Le leader assemble le bloc final, mais ne peut plus décider arbitrairement de son contenu sous peine de produire un bloc invalide.
Le cœur de l’innovation est le concept de Multiple Concurrent Proposers (MCP). Au lieu d’un seul leader qui fait tout, Constellation sépare les rôles en couches distinctes avec des contre-pouvoirs cryptographiques.

Les utilisateurs envoient leurs transactions à un ou plusieurs des 16 proposeurs. Chaque proposeur envoie ses transactions sous forme de pslices aux 256 attesteurs. Les attesteurs horodatent et transmettent tout au leader, en produisant des attestations cryptographiques. Le leader doit inclure toute transaction ayant reçu suffisamment d’attestations (au moins 64 sur 256). S’il ne le fait pas, le bloc est invalide.
Le protocole introduit un cycle économique de 50 ms, le tick le plus rapide de toute blockchain décentralisée en production, découplé du délai de propagation réseau grâce à des horloges synchronisées.
Ce n’est pas un temps de bloc, c’est un tick économique : l’intervalle minimal d’inclusion de transactions, découplé du délai réseau global. Le cycle est calculé en divisant le timestamp Unix en nanosecondes par 50 000 000. Les attesteurs s’appuient sur des horloges synchronisées (GPS, chrony, Google TrueTime), ce qui découple la fréquence d’inclusion des transactions du délai de propagation réseau.
Le protocole sert de préprocesseur à Alpenglow, la refonte du consensus Solana ciblant une finalité à 150 ms, avec un déploiement mainnet visé au Q3 2026.

Face à Hyperliquid et ses 21 nœuds contrôlés à ~81% par sa fondation, Solana Constellation mise sur la décentralisation profonde ( avec ses 1000 validateurs) et des garanties formelles anti-censure intégrées au protocole. Cependant, ni Constellation ni Alpenglow ne sont encore en ligne alors qu’Hyperliquid est en production et fonctionne avec un temps de bloc de 70ms et une finalité de bout en bout de 200 ms.
Solana a encore beaucoup de travail ! Le testnet de Solana Alpenglow est prévu pour mai 2026 (source Helius) et la mise à jour sur le mainnet ne se présentera probablement pas avant le 2ème semestre 2026.
Ce Coin Hebdo est soutenu par OKX
Ce Coin Hebdo est soutenu par OKX, l’un des plus importants exchanges de cryptomonnaies au monde.
OKX offre une expérience complète pour acheter, trader, vendre et gérer ses crypto monnaies avec des outils adaptés aussi bien aux débutants qu’aux traders expérimentés : trading spot, margin spot, wallet multichain OKX Wallet, agrégateur de swap et bridge.
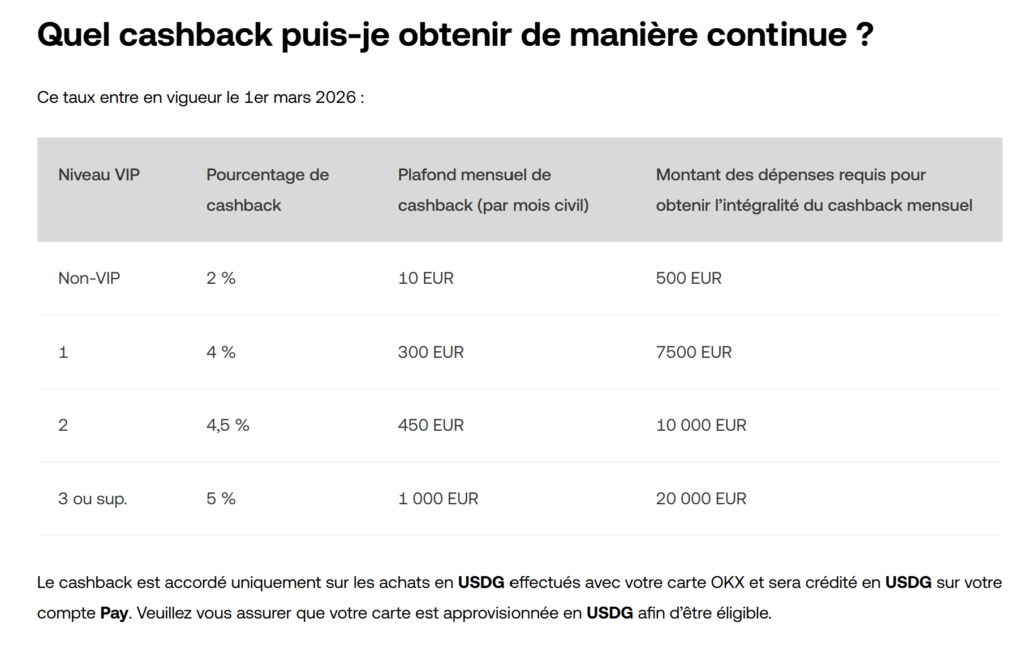
OKX Europe propose depuis peu une carte bancaire crypto Mastercard compatible Apple Pay et Google Pay, avec 2 % de cashback sur tous vos paiements.
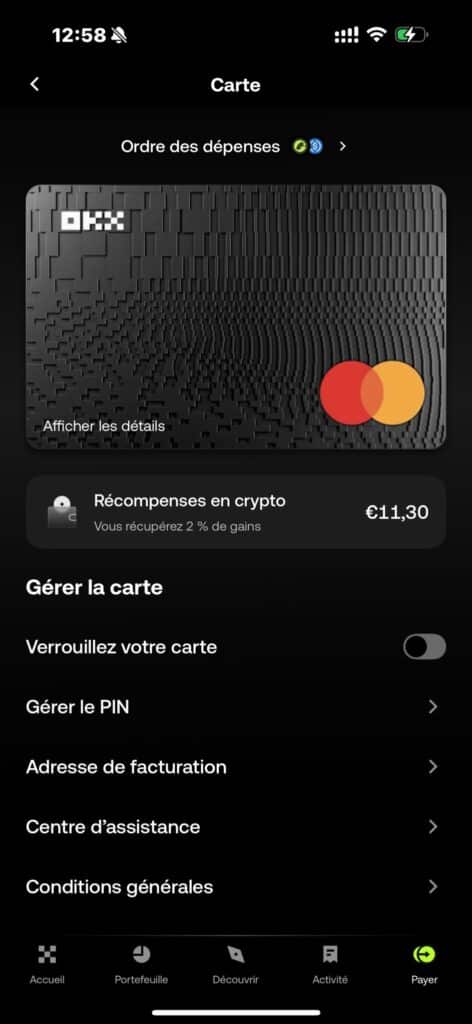
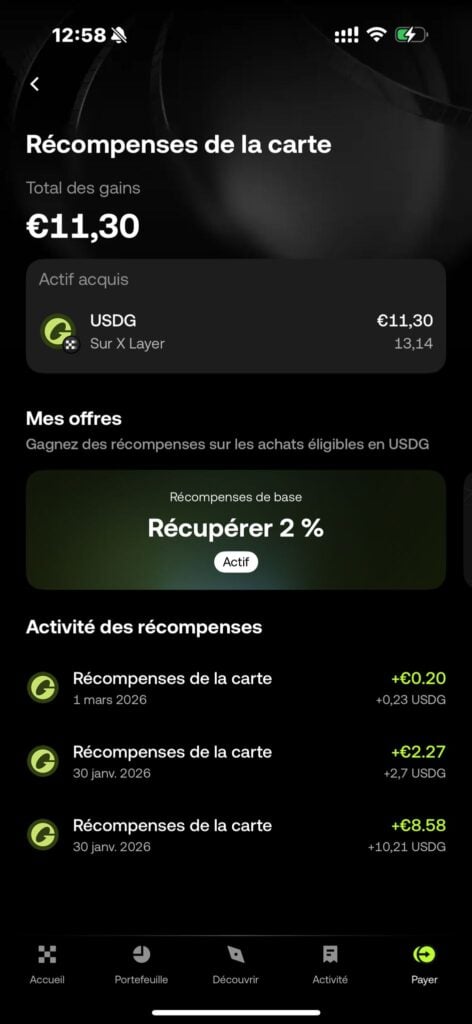
Le cashback est versé en USDG directement sur votre solde OKX Pay sous 24h, et plafonné à 10 € de gains par mois (soit environ 500 € de dépenses cumulées).
Pour en profiter : alimentez votre solde OKX Pay en USDG avant d’utiliser la carte. La carte fonctionne partout où Mastercard est accepté, en magasin comme en ligne 👉 Retrouvez notre tutoriel complet ici pour configurer votre carte en quelques minutes.
Google dévoile TurboQuant : l’algorithme qui compresse la mémoire des LLM par 6 sans perte de précision
Google Research a publié TurboQuant, un algorithme de compression qui réduit la mémoire du cache KV (Key – Value) des grands modèles de langage par un facteur 6, en quantifiant les données à 3 bits par valeur contre 16 ou 32 habituellement.
Le cache KV, qui stocke les représentations intermédiaires de chaque token durant l’inférence, constitue le principal goulot d’étranglement quand les fenêtres de contexte dépassent 100 000 tokens, c’est-à-dire lorsque les conversations durent ou dans les gros projets de développement informatique.

TurboQuant va bientôt s’intégrer aux principaux moteurs d’inférence open source (llama.cpp, vLLM, Ollama etc.) et changer la donne pour l’inférence locale sur les cartes graphiques (GPU) grand public.
Prenons l’exemple concret d’un modèle Qwen 3.5 27B en quantisation Q4 sur une RTX 5080 (16 Go de VRAM).
Les poids du modèle occupent environ ~18 Go, ce qui sature déjà la mémoire disponible. Avec un cache KV classique en FP16, une fenêtre de contexte de 16k tokens ajoute environ 4 Go supplémentaires, soit un total de ~22 Go. Résultat : OOM (out of memory), et le contexte réaliste se limite à ~4k tokens, traduction : on ne peut clairement pas tenir une conversation ou gérer un projet de code avec si peu de tokens à notre disposition.
Avec TurboQuant en 3 bits, ce même cache KV tombe à ~0,7 Go (une réduction de 83%), portant le total à ~18,7 Go. Le modèle passe en offload partiel (une partie des couches reste en RAM système en plus de la VRAM de la carte graphique), mais le contexte réaliste grimpe à ~16k tokens. Le cache KV n’est plus le problème c’est le modèle lui-même qui sature la VRAM.

La RTX 4090 (24 Go) illustre mieux le gain. Le modèle Qwen 3.5 27B en Q4 occupe ~18 Go de poids.
Un cache KV en FP16 à 32k tokens ajoute ~8 Go -> total ~26 Go, la carte affiche OOM et le contexte tombe à ~12k tokens.
Avec TurboQuant 3 bits, le cache passe à ~1,5 Go. Total : ~19,5 Go.
Tout tient en VRAM, zéro offload. Le contexte exploitable monte à ~64k+ tokens, la latence d’attention baisse d’un facteur ~5x. Une carte qui bloquait sur 12k tokens de contexte fait maintenant tourner un document de 50 pages ou une codebase multi-fichier sans appel API.

La communauté open source s’est mise en mouvement. Une implémentation PyTorch complète existe déjà sur GitHub, testée sur Qwen 2.5-3B avec un RTX 3060, confirmant une fidélité d’attention de 99,5% à 3 bits.
Un contributeur de llama.cpp a soumis une implémentation C/CUDA avec des résultats MSE correspondant exactement au papier. Une demande d’intégration a été ouverte sur vLLM, et l’implémentation officielle de Google est attendue vers le 2ème trimestre 2026 !
Les marchés vendent d’abord, réfléchissent après : le paradoxe de Jevons appliqué à la DRAM
Les marchés ont vendu les valeurs mémoire dans la foulée de l’annonce TurboQuant mais TurboQuant compresse l’inférence, pas l’entraînement…
Micron a perdu 12% sur la semaine, de ~426$ à ~357$. SanDisk a perdu 11% en une séance. SK Hynix et Kioxia ont décroché de 6% chacun à Séoul et Tokyo, Samsung de 5%. Western Digital (-4,7%), Seagate (-4%), Lam Research (-3%) ont suivi. Le marché lit la situation au premier degré : 6x moins de mémoire par inférence = moins de DRAM vendue.
Et Micron vient d’annoncer plus de 25 milliards de dollars de capex pour 2026, un pari qui perd de sa marge de sécurité si la demande mémoire ralentit.

Le raccourci ne tient pas. TurboQuant compresse le cache KV en inférence. Il ne touche pas à l’entraînement, premier poste de consommation HBM chez Google, Microsoft et les autres hyperscalers. Morgan Stanley a invoqué le paradoxe de Jevons : baisser le coût par token rend l’inférence viable pour des cas d’usage qui ne l’étaient pas, ce qui augmente la consommation totale de mémoire.
Le précédent existe : le sell-off DeepSeek R1 de janvier 2025 avait provoqué la même panique. Deux trimestres plus tard, les budgets IA des hyperscalers battaient des records.
Pour les investisseurs qui regardent au-delà du trimestre en cours, ce type de sell-off sur panique algorithmique a historiquement offert des points d’entrée.
Le paradoxe de Jevons : pourquoi consommer moins de mémoire RAM pourrait en faire vendre plus
En 1865, l’économiste William Stanley Jevons observe que la machine à vapeur de Watt consomme moins de charbon que ses prédécesseurs. La demande en charbon ne baisse pas. Elle explose.
Le moteur plus efficace rend la vapeur rentable pour des usages qui n’existaient pas avant, les usines, les locomotives, les navires. L’efficacité élargit le marché au lieu de le réduire. Ce mécanisme s’est répété à chaque cycle technologique.
La compression JPEG n’a pas réduit les ventes de stockage, elle a permis la photo numérique grand public, puis les smartphones à 100 photos par jour. Les codecs H.264 et H.265 n’ont pas tué la demande de disques durs, ils ont rendu le streaming 4K viable et Netflix a englouti plus de bande passante que le web entier d’avant.

TurboQuant suit la même logique. Diviser le cache KV par 6 ne signifie pas que les hyperscalers vont commander 6 fois moins de mémoire HBM. Cela signifie qu’un GPU qui gérait 12k tokens de contexte en gère maintenant 64k+ et que des startups qui ne pouvaient pas se payer l’inférence longue vont la déployer.
En théorie, avec TurboQuant, des cas d’usage bloqués par le coût comme les agents autonomes ou les conversations multi-documents deviennent rentables !
Aave V4 veut transformer 6 milliards $ de liquidités dormantes en machine à rendement
Aave Labs construit un module de réinvestissement pour V4. Sa cible : 6 milliards de dollars immobiles sur les 20 milliards de dépôts stablecoins du protocole.
Ce capital, conservé en réserve pour garantir les retraits instantanés, ne génère actuellement aucun rendement important. Le module va déployer ces réserves excédentaires dans des stratégies à faible risque approuvées par la gouvernance d’AAVE (bons du Trésor à court terme, marchés monétaires ou positions delta-neutral) tout en préservant un accès instantané aux fonds, sans période de blocage.
L’architecture d’AAVE V4 repose sur un hub de liquidité central qui agrège tous les actifs déposés, puis les redistribue vers plusieurs marchés de prêt appelés spokes, chacun disposant de ses propres paramètres de risque. Le module de réinvestissement s’intègre dans ce système : il surveille les réserves excédentaires, les alloue automatiquement quand la demande d'emprunt baisse, et rapatrie les fonds dès qu’elle remonte.
La configuration s’effectue par actif, permettant des stratégies et seuils d’activation différenciés selon le profil de risque de chaque token.
Selon les simulations historiques d’Aave Labs, réinvestir ces liquidités excédentaires à des taux proches du SOFR aurait fait passer les rendements moyens des stablecoins de 4% à 4,9%, soit une hausse relative de 25%.
Pour rappel : la date de lancement d’AAVE V4 n’est pas fixée.
Binance durcit ses règles : les nouvelles sanctions contre les market makers manipulateurs
Binance a publié six signaux d’alarme pour repérer les market makers qui manipulent les marchés.
Parmi eux : des ventes qui ne collent pas aux calendriers de déblocage, du trading orienté dans un seul sens, des dépôts coordonnés sur plusieurs exchanges, du volume sans mouvement de prix.
Ces pratiques frappent surtout les nouveaux listings, quand les carnets d’ordres sont encore minces et que chaque trade pèse sur le prix. La mise à jour remplace le cadre généraliste de février 2025 par des critères concrets.
Les projets crypto doivent désormais divulguer l’identité complète de leurs market makers, y compris l’entité légale et les termes contractuels. Binance interdit les accords de partage de profits et de rendements garantis entre projets et market makers, des structures qui incitaient ces derniers à gonfler les prix ou la volatilité pour atteindre des objectifs contractuels. Les contrats de prêt de tokens doivent préciser l’usage autorisé des actifs.
Ces nouvelles mesures arrivent dans un contexte de critiques croissantes contre les pratiques de listing de Binance, certains VCs et fondateurs accusent la plateforme d’exiger jusqu’à 15% du supply d’un token pour un listing.
Les market makers qui enfreignent ces règles risquent un blacklisting de la plateforme Binance. Pour les investisseurs, ces changements pourraient se traduire par des spreads plus larges et une volatilité accrue sur les tokens récemment listés, la liquidité artificielle étant progressivement éliminée. D’autres exchanges majeurs pourraient adopter des règles similaires dans les mois à venir, Binance fixant de fait un nouveau standard de transparence pour l’industrie.
Cet article vous a plu ? Recevez les prochains par email
Rejoignez +40 000 abonnés. L'essentiel du marché crypto dans votre boîte mail, tous les 2 jours.




